https://philosophy-chat.com/
Over the last few months, I’ve been working on a Q&A application for academic philosophy questions. I now have V1 deployed on the web! Please be patient, as it commonly fails after the first question and the runtime is ~10 seconds per question. But it works, and I’m proud of it.
This project was motivated by 1) my desire to personally use the site as a way to deepen my knowledge of philosophy and 2) as a proof-of-concept LLM application that can give sources and make up wrong information less. More than just giving an accurate answer, the program provides the sections of text that it references and links, so you could have a good jumping off point to clarify questions.
A slightly different (and older) version of the backend is publicly available on my Github, and as I make the frontend and API code more readable, I may release it too.
Here’s what it looks like.
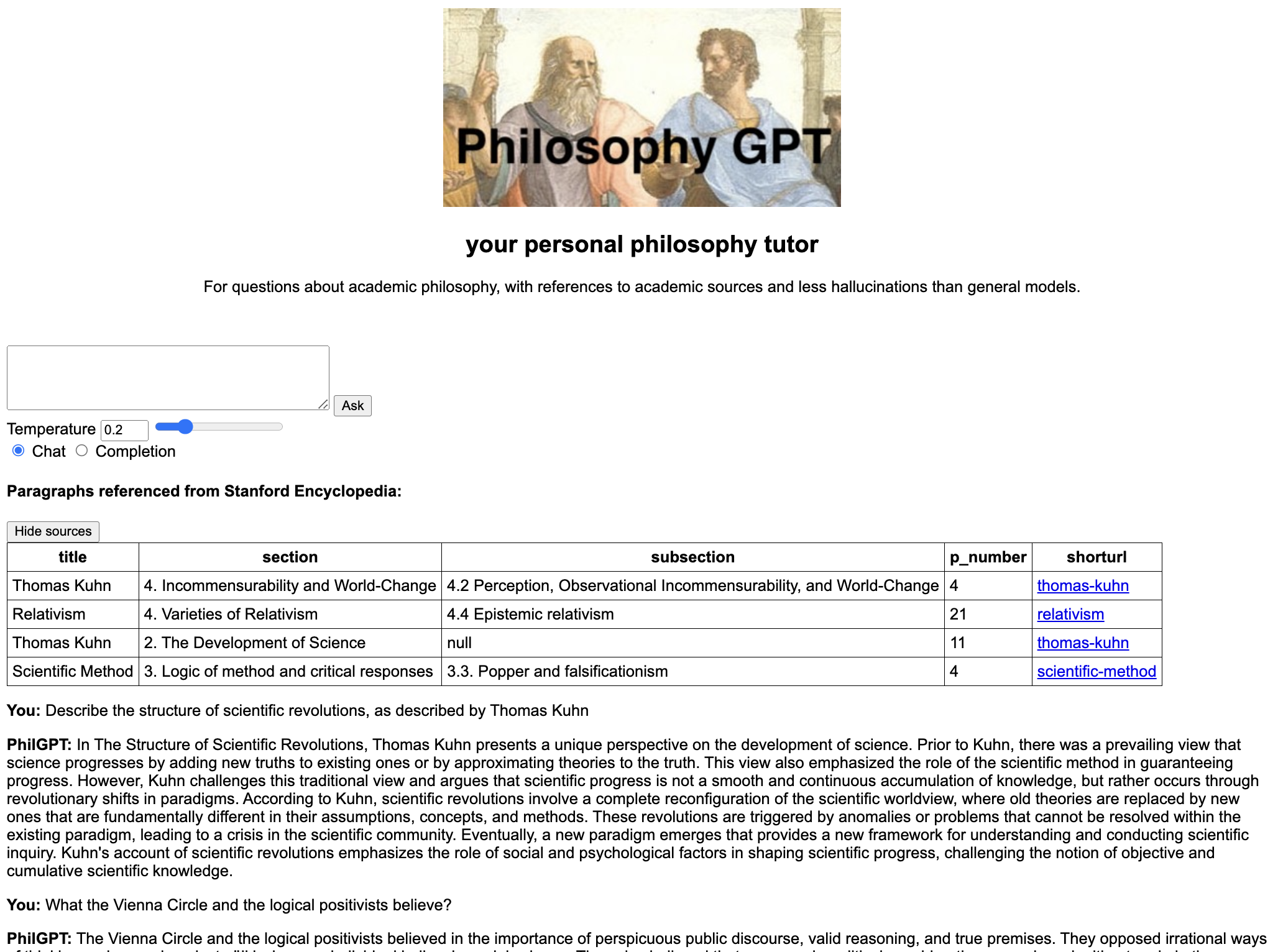
Technical description
I wrote an API in Python Flask, which receives a question from a user, and returns the written response and a JSON of sources. This runs on a Platform as a Service (which fails randomly). My frontend uses Svelte (hosted via Netlify) and calls the API when a user submits a question, and formats the sources in return.
Each paragraph from the Stanford Encyclopedia of Philosophy (SEP) has been embedded and stored locally. When a user asks a question, their question is embedded and compared to the entirety of SEP using functions from FAISS to find the most similar few paragraphs in our large dataset. A number of these paragraphs are appended to the question as factual context, and fed to the OpenAI API. The response is returned as well as a table of the paragraphs that were used as context for the model.
Since I started this project in February, there are many similar projects and tutorials on different datasets. I only referenced an old version of the OpenAI cookbook and derived most of the rest.
I chose to avoid using a database for system simplicity, so every time a question is asked, the entirety of the dataset is loaded into memory where the search is done. This takes 3GB of RAM and causes the program to crash on occasion. Meaning, there are massive unrealized gains in performance if restructured to do search and retrieval of paragraphs in a vector database. All of the compute-heavy steps are just an exercise in creating better prompts for an effective large language model, and providing a basic search function over a large collection of potentially relevant paragraphs.
A lot of time was spent on preprocessing and embedding the data, which I pulled from Hugging Face. Embedding a large amount of data takes a long time, and functions like api_request_parallel_processor.py help things quite a bit.
There are several improvements that could be made, in speed and in quality of answer.